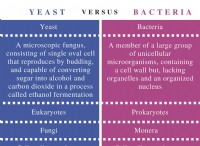
분류에 중요한 요소 :
1. 데이터 품질 및 준비 :
* 클린 데이터 : 부정확 한, 누락 또는 일관성이없는 데이터는 모델 성능에 크게 영향을 줄 수 있습니다. 데이터 정리 및 전처리 단계가 중요합니다.
* 기능 엔지니어링 : 관련 기능을 선택하고 적절하게 변환하면 모델 정확도를 향상시킬 수 있습니다.
* 데이터 밸런싱 : 클래스 불균형 (한 클래스가 다른 클래스보다 훨씬 더 많은 예를 가지고있는 경우)은 모델을 대다수 클래스에 편향시킬 수 있습니다. 이를 해결하려면 오버 샘플링, 언더 샘플링 또는 비용에 민감한 학습 사용과 같은 기술이 필요합니다.
2. 알고리즘 선택 :
* 데이터 특성 : 다른 알고리즘은 다른 유형의 데이터에서 더 잘 수행됩니다 (예 :선형 대 비선형, 고차원 대 저 차원).
* 모델 복잡성 : 소규모 데이터 세트 또는 해석 성이 중요 할 때 더 간단한 모델이 바람직 할 수 있지만 복잡한 관계를 가진 대형 데이터 세트에는보다 복잡한 모델이 필요할 수 있습니다.
* 계산 자원 : 일부 알고리즘은 계산적으로 비싸고 상당한 리소스가 필요합니다.
3. 평가 지표 :
* 정확도 : 전체 올바른 분류를 측정합니다.
* 정밀 : 측정 모든 예측 된 양성 인스턴스 중에서 올바르게 분류 된 양성 인스턴스의 비율을 측정합니다.
* 리콜 : 모든 실제 긍정적 인 사례 중에서 올바르게 분류 된 긍정적 인 사례의 비율을 측정합니다.
* f1- 점수 : 정밀도와 리콜 사이의 균형.
* auc-roc : 수신기 작동 특성 곡선 아래의 영역을 측정하는데, 이는 불균형 데이터 세트에 대한 모델 성능의 좋은 지표입니다.
4. 해석 및 설명 :
* 모델 투명성 : 모델이 어떻게 예측을하는지 이해하는 것이 특정 응용 프로그램에서 중요 할 수 있습니다.
* 기능 중요성 : 가장 영향력있는 기능을 식별하면 근본적인 관계에 대한 귀중한 통찰력을 제공 할 수 있습니다.
* 편견과 공정성 : 다른 하위 그룹에서 모델의 성능을 평가하면 잠재적 편향을 식별하는 데 도움이 될 수 있습니다.
5. 컨텍스트 및 응용 프로그램 :
* 비즈니스 요구 사항 : 응용 프로그램마다 우선 순위가 다를 수 있습니다 (예 :정밀도 최대화 대 리콜 최대화).
* 도메인 전문 지식 : 도메인 지식을 통합하면 모델 성능과 해석 성을 크게 향상시킬 수 있습니다.
* 윤리적 고려 사항 : 분류 모델의 잠재적 영향을 고려하고 윤리적이고 책임감있게 사용되도록하는 것이 중요합니다.
6. 지속적인 개선 :
* 모델 모니터링 : 모델의 성능을 정기적으로 평가하고 필요에 따라 조정합니다.
* 재교육 : 정확도를 유지하기 위해 새로운 데이터로 모델을 업데이트합니다.
* 실험 : 모델 성능을 최적화하기 위해 다양한 알고리즘, 기능 및 하이퍼 파라미터 튜닝을 탐색합니다.
이러한 요소를 신중하게 고려하면 응용 프로그램의 특정 요구를 충족하는 효과적이고 강력한 분류 모델을 구축 할 수 있습니다.