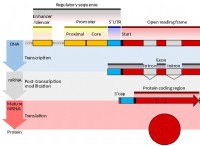
1. 데이터 구성 :
* 분류 : 공유 특성을 기반으로 객체 또는 정보를 그룹화합니다. 이것은 생물학 (유기체 분류), 화학 (요소 분류) 및 천문학 (천체 분류)의 기본입니다.
* 데이터 분석 : 종종 버블 정렬, 삽입 정렬 또는 병합 정렬과 같은 알고리즘을 사용하여 데이터를 의미있는 순서로 배열합니다. 이것은 과학 데이터의 트렌드, 패턴 및 특이 치를 식별하는 데 도움이됩니다.
2. 구성 요소 분리 :
* 정제 : 원하는 물질을 혼합물로부터 분리한다. 이것은 화학 (특정 화합물 분리), 생물학 (DNA 또는 단백질 추출) 및 공학 (정제수)에 사용됩니다.
* 분별 : 물리적 또는 화학적 특성에 따라 혼합물을 성분으로 분리합니다. 예제는 다음과 같습니다.
* 크로마토 그래피 : 고정 단계에 대한 친화력을 기반으로 구성 요소를 분리합니다.
* 증류 : 끓는점에 따라 액체를 분리합니다.
* 여과 : 액체에서 고체를 분리합니다.
3. 실험 설계 :
* 무작위 배정 : 편견을 제거하기 위해 다른 그룹에 피험자 또는 치료를 무작위로 할당합니다. 이것은 제어 된 실험을 수행하는 데 필수적입니다.
과학 분류의 예 :
* 다른 유형의 조류를 식별하기 위해 연못 물 샘플을 분류하는 생물 학자.
* 크로마토 그래피를 사용하여 화학 물질의 혼합물을 분리하는 화학자.
* 물리학자가 입자 가속기의 데이터를 분석하여 새로운 입자를 식별합니다.
요약하면, 과학 분류는 우리 주변의 세계에 대한 더 깊은 이해를 얻기 위해 데이터 또는 자료를 조직, 분리 및 배열하는 것이 포함됩니다.