1. DNA 추출 :
* 샘플 수집 : 생물학적 물질 (혈액, 타액, 모발 등) 샘플은 해당 개인에게서 가져옵니다.
* DNA 분리 : 특수 기술은 샘플의 세포로부터 DNA를 분리하고 정제하는 데 사용됩니다.
2. DNA 분석 :
* 마커 선택 : 개인 ( "마커"라고 함)마다 다른 것으로 알려진 DNA의 특정 영역은 분석을 위해 선택됩니다. 이 마커는 다음을 포함 할 수 있습니다.
* 짧은 탠덤 반복 (strs) : 이들은 개인 간의 반복 수가 다른 짧고 반복되는 DNA 서열입니다.
* 단일 뉴클레오티드 다형성 (SNP) : 이들은 개인들 사이에서 흔한 변이 인 DNA 서열의 단일 기본 차이이다.
* DNA 증폭 : 선택된 마커는 중합 효소 연쇄 반응 (PCR)이라는 기술을 사용하여 증폭된다. 이것은 마커의 많은 사본을 만들어 분석하기 쉽게 만듭니다.
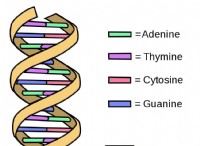
* DNA 시퀀싱 : 증폭 된 DNA는 각 마커에서 뉴클레오티드 (A, T, C, G)의 특정 순서를 결정하기 위해 서열화된다.
3. DNA 프로파일 비교 :
* 프로파일 생성 : 각 마커에 대한 서열 정보는 알려진 변형의 데이터베이스와 비교됩니다. 이것은 각 개인에 대해 고유 한 DNA 프로파일을 만듭니다.
* 관련성과 계산 : 개인의 DNA 프로파일은 공유하는 마커 수를 확인하기 위해 비교됩니다.
* 친척은 더 많은 마커를 공유합니다. 공유 마커 수가 클수록 개인이 더 밀접하게 관련되어 있습니다.
* 통계 분석 : 관련성의 정도는 모집단의 각 마커의 빈도를 고려하는 통계 알고리즘을 사용하여 계산됩니다.
예 :
* 친자 테스트 : 자녀의 DNA 프로파일은 아버지가 생물학적 부모인지 판단하기 위해 아버지의 것과 비교됩니다.
* 법의학 조사 : 범죄 현장의 DNA는 용의자의 DNA 프로파일과 비교됩니다.
* 계보 : DNA 테스트는 조상을 추적하고 먼 친척을 찾는 데 도움이 될 수 있습니다.
중요한 점 :
* 정확도 : 관련성을 결정하기위한 DNA 분석은 특히 여러 마커를 사용할 때 매우 정확합니다.
* 윤리적 고려 사항 : DNA 검사의 윤리적 영향을 인식하고 이러한 목적으로 DNA를 사용하기 전에 사전 동의를 얻는 것이 필수적입니다.
* 개인 정보 : 유전자 정보는 민감하며 DNA 검사를받는 개인의 프라이버시를 보호하는 것이 중요합니다.
DNA 분석 및 관련성에 대해 더 구체적인 질문이 있으면 알려주세요!