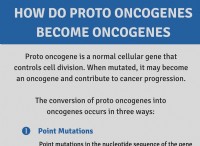
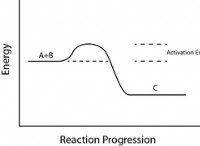
1. 유전자 코드 및 단백질 합성 :
* Blueprint로서 DNA : 단백질 제조에 대한 지침은 우리의 DNA에서 암호화됩니다. 우리의 DNA 내의 각 유전자는 단백질에서 아미노산의 순서를 명시하는 뉴클레오티드 (A, T, C, G)의 서열을 함유한다.
* 전사 및 번역 : DNA 서열은 먼저 유전자 정보를 리보솜에 전달하는 메신저 RNA (mRNA)로 전사된다. 이어서 리보솜은 유전자 코드에 따라 mRNA 서열을 아미노산 사슬로 변환한다.
* 다양한 아미노산 : 단백질을 만드는 데 사용될 수있는 20 개의 아미노산이 있으며, 이들 아미노산의 순서는 단백질의 독특한 구조와 기능을 결정합니다.
2. 단백질 다양성 메커니즘 :
* 대체 스 플라이 싱 : 단일 유전자는 대안 적 스 플라이 싱을 통해 다수의 단백질 이소 형을 생성 할 수있다. 이 과정은 유전자 내에서 상이한 엑손 (코딩 영역)의 다른 조합을 선택하여 상이한 mRNA 전 사체 및 궁극적으로 다른 단백질을 초래한다.
* 번역 후 수정 : 합성 후, 단백질은 인산화, 글리코 실화 또는 아세틸 화과 같은 다양한 변형을 겪을 수있다. 이러한 변형은 세포 내 단백질의 활성, 안정성 또는 위치를 변경할 수 있습니다.
* 단백질-단백질 상호 작용 : 단백질은 거의 분리되지 않는 경우가 거의 없습니다. 그들은 서로 상호 작용하여 더 큰 복합체를 형성하여 단백질 기능의 다양성을 더욱 증가시킬 수 있습니다.
* 유전자 복제 및 진화 : 진화 시간에 걸쳐, 유전자는 복제 될 수 있으며, 이러한 중복 유전자는 새로운 단백질 기능을 유발하는 돌연변이를 축적 할 수있다.
3. 계산 도구 및 데이터베이스 :
* 생물 정보학 : 과학자들은 계산 도구를 사용하여 DNA 및 단백질 서열을 분석하고 단백질 구조를 예측하며 단백질 상호 작용을 식별합니다.
* 단백질 데이터베이스 : Uniprot 및 PDB와 같은 대형 데이터베이스는 수백만 개의 단백질 서열, 구조 및 기능에 대한 정보를 저장합니다. 이 데이터베이스를 통해 연구원들은 특정 단백질을 검색하고 특성을 분석 한 후 다른 단백질과 비교할 수 있습니다.
4. 실험 기술 :
* 질량 분석법 : 이 기술은 샘플에서 단백질을 식별하고 정량화하는 데 사용될 수 있으며, 과학자들은 프로테옴 (유기체 또는 세포의 전체 단백질 세트)을 연구 할 수 있습니다.
* X- 선 결정학 및 NMR 분광학 : 이러한 기술은 단백질의 3 차원 구조를 결정하는 데 사용되어 기능에 대한 통찰력을 제공합니다.
요약 : 살아있는 유기체에서 발견되는 수백만 개의 단백질은 유전자 코드, 단백질 합성, 다양한 단백질 변형 메커니즘 및 진화 과정 사이의 복잡한 상호 작용의 결과입니다. 과학자들은 계산 도구, 실험 기술 및 데이터베이스의 조합을 사용 하여이 광대 한 단백질 우주를 연구하고 이해합니다.