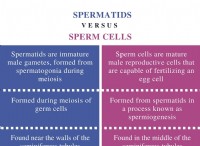
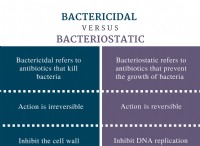
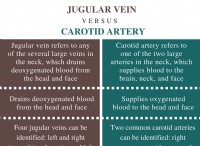
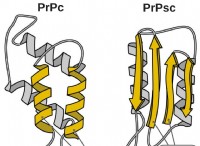
데이터 관련 과제 :
* 데이터 볼륨 및 복잡성 : 생물학적 데이터 세트는 게놈, 단백질 학, 대사 및 임상 데이터를 포함하여 방대하고 끊임없이 성장하고 있습니다. 이 방대한 양의 데이터를 관리, 저장 및 처리하는 것은 중요한 과제입니다.
* 데이터 이질성 : 다양한 데이터 세트가 종종 다양한 기술과 플랫폼을 사용하여 생성되어 데이터 불일치와 통합 및 분석의 어려움이 발생합니다.
* 데이터 품질 및 신뢰성 : 데이터 생성 및 처리 중에 오류, 편견 및 불일치가 발생할 수 있으며, 신중한 데이터 품질 관리 및 검증이 필요합니다.
* 데이터 개인 정보 및 보안 : 민감한 개인 정보는 종종 생물학적 데이터와 관련이 있으며, 데이터 액세스 및 공유에 대한 강력한 보안 조치 및 윤리적 고려 사항이 필요합니다.
계산 도전 :
* 알고리즘 개발 : 복잡한 생물학적 데이터를 분석하기위한 새롭고 효율적인 알고리즘, 특히 서열 정렬, 유전자 찾기, 단백질 구조 예측 및 네트워크 분석과 같은 작업에 대해.
* 고성능 컴퓨팅 : 대규모 생물학적 데이터를 처리하려면 병렬 및 분산 컴퓨팅에 대한 강력한 계산 리소스와 전문 지식이 필요합니다.
* 데이터 시각화 및 해석 : 복잡한 분석 결과를 시각화하고 해석하는 것은 생물학적 통찰력을 이해하고 의미있는 결론을 도출하는 데 중요합니다.
생물학적 도전 :
* 생물학적 복잡성 : 살아있는 시스템은 엄청나게 복잡하며 여러 수준의 상호 작용을 포함하여 생물학적 과정을 모델링하고 이해하는 데 어려움을 겪습니다.
* 생물학적 지식 부족 : 데이터 생성의 발전에도 불구하고, 많은 생물학적 시스템에 대한 우리의 이해는 여전히 불완전한 상태로 남아있어 데이터의 해석과 예측 모델의 개발을 방해합니다.
* 임상 실습으로의 번역 : 연구 결과와 임상 적용 사이의 격차를 해소하는 것은 생물 정보학 발견을 환자의 실질적인 이점으로 번역하는 데 중요합니다.
다른 도전 :
* 학제 간 협력 : 생물 정보학은 복잡한 연구 문제를 해결하기 위해 생물 학자, 컴퓨터 과학자, 통계 학자 및 기타 전문가 간의 긴밀한 협력이 필요합니다.
* 자금 및 인프라 : 생물 정보학 연구 및 개발을 지원하는 데 적절한 자금과 고성능 컴퓨팅 인프라에 대한 접근이 필수적입니다.
* 교육 및 훈련 : 생물 정보학에 대한 전문 지식을 갖춘 숙련 된 인력 개발은이 분야의 증가하는 수요를 충족시키는 데 중요합니다.
이러한 과제를 해결하려면 다양한 분야의 지속적인 연구, 혁신 및 협력이 필요합니다. 계산 능력, 데이터 관리 기술 및 생물 정보학 도구의 지속적인 발전은 과학적 발견을위한 생물학적 데이터의 잠재력을 해제하고 인간 건강을 개선하는 데 중요한 역할을 할 것입니다.